Questo blog contiene una breve introduzione alla programmazione della Unix shell csh/tcsh. Per altri tipi di shells, il lettore può consultare manuali dedicati a questo argomento riportati nella bibliografia alla fine di questa questo blog.
Uno script autoeseguibile in csh shell inizia con la linea:
#! /bin/csh -f
Il #!∕bin∕csh è il comando usato per rendere eseguibile lo shell script (in questo esempio si fa riferimento alla csh shell ma è lo stesso con altri tipi di shell). L’ opzione –f è usata per un avvio veloce della shell ovvero non viene letto il file diconfigurazione .cshrc presente nella home directory. Il file di script deve essere reso eseguibile con il comando:
chmod + x script.com
e quindi si può eseguire digitando il nome del file
script.com
Variabili di shell
Il comando set can be used to set the value of the shell variable.
set c = 299.792.458
Si fa riferimento al valore di una variabile di shell mettendo un $ prima del nome
della variabile o racchiudendola in una parentesi graffa.
echo ${c}
Nel caso di variabili alphanumeriche, le parentesi graffe possono essere utilizzate
per aggiungere alla variabile un’altra stringa di caratteri.
Esempio
Questo script elimina il file di nome prog1.c presente nella directory corrente. È
possibile separare da un nome il prefisso e il suffisso usando speciali attributi. Il
seguente esempio stampa mostra come usare questi attributi.
Esempio
in uscita lo script stampa
dat
è possibile assegnare valori numerici a variabili come:
set BCONST = (0.0083144621)
o a un singolo elemento di una variabile di lista
set VX [3] = 11.01
Il numero di elementi in una variabile di lista può essere stampato utilizzando il
prefisso con un #. Il comando echo $#VX stamperà 3.
Il comando può essere utilizzato per i calcoli. Ad esempio, se si sono le variabili di
shell $X e $Y, possibile impostare una terza variabile $Z alla loro somma usando
l’espressione
Z = $X + $Y
Mentre i due comandi
Z++
Z–
incrementano e decrementano di una unità il valore di Z.
Variabili Speciali
La shell si riserva alcuni dei nomi delle variabili per scopi specifici. Una variabile importante è la variabile di shell argv. Questa variabile elenco contiene gli argomenti (parametri) che vengono forniti dopo il nome dello script di shell nella linea di comando al momento della sua esecuzione. I parametri sono accessibili come elementi della lista $argv [1], $argv [2], ecc. o come $1, $2, ecc Il numero di tali argomenti $#argv.
Per esempio, si consideri il seguente script che valuta le quattro operazioni aritmetiche tra due numeri di ingresso.
2set val1 = $argv[1]
3set val2 = $argv[3]
4 switch ($argv[2])
5 case [+]:
6 echo @ val1 + val 2
7 breaksw
8 case [–]:
9 echo @ val1 ? val2.
10 breaksw
11 case [*]:
12 echo @ val1 * val2.
13 breaksw
14 case [*]:
15 echo @ val1 / val2.
16 breaksw
17 default:
18 echo The operation was not recognized.
19 breaksw
20 endsw
21end
Per usare lo script, copiatelo in un file chiamato eval e provate ad eseguirlo aggiungendo due numeri dopo eval (eval 12.3 + 4.5). Lo script utilizza una istruzione di controllo che verrà descritta nel prossimo paragrafo.
Istruzioni di controllo del flusso del programma
Il linguaggio della c-shell ha costrutti per l’esecuzione condizionale quali l’IF-THEN-ELSE
e l’istruzione SWITCH (che è stata già utilizzata nel paragrafo precedente), e per l’esecuzione iterativa (quali i cicli FOREACH e WHILE) . Questi comandi vengono usati per controllare il flusso del programa permettendo di eseguire blocchi di commandi in sequito al verificarsi di una o piuù condizioni logiche sul contenuto delle variabili del programma. Di seguito vedremo brevemente il loro uso.
Dichiarazione esecuzione condizionale (if-then-else)
La sintassi della condizione if-then-else può essere data nella forma
if (espressione) <comando>
oppure in quella più complessa
<blocco di comandi>
else
<blocco alternativo di comandi>
endif
Il valore vero o falso dell’espressione espressione determina l’esecuzione del blocco
di comandi o del blocco alternativo dopo else.
Esempio
2 echo ”Error! Usage: eval val1 operation (+|-|*|/) val2” \\
3 else \\
4 set val1 = $argv[1]
5 set val2 = $argv[3]
6 endif
Il comando switch è stato (utilizzato nel’esempio del paragrafo precedente), è un comando condizionale con diramazione multipla. La forma generale del comando è la seguente:
case pattern1:
<blocco comandi 1>
breaksw
case pattern2:
<blocco comandi 2>
breaksw
default:
<blocco di programma di default>
endsw
Il valore di string viene successivamente confrontato con i vari casi pattern*. In questo modo il controllo del programma viene diretto al blocco di comandi del caso per il quale il valore di confronto risults vero.
Esecuzione iterativa
Questi comandi vengono usati per iterare un blocco di comandi per un numero fissato
di cicli o fino a quando una condizione logica non venga verificata.
Il ciclo while ha la seguente sintassi:
<lista comandi>
end
La lista di comandi sarà eseguita fino a quando il valore logico dell’espressione in
parentesi è vera. Il ciclo foreach ha la seguente sintassi:
<lista istruzioni>
end
La lista del comandi viene eseguito per ogni parola nella lista wordlist e ogni
volta la variabile var conterrà un valore della lista.
Esempio
Lo script che segue utilizza il ciclo foreach per convertire in formato JPEG varie imagini in formato TIFF presenti nella directory dove viene lanciato. Il programma legge tutti i file aventi estensione .tif assegnandoli alla variabile $d li stampa (linea 4).Definisce una variabile $f (linea 5) com il nome del file con estensione .jpg e utilizza il programma convert per convertire il formato dell’immagine.
2 set f = $1
3 foreach d (*.tif)
4 echo FOUND: ${d}
5 set f=${d:r}.jpg
6 convert $d $f
7 end
Il linguaggio awk
L’ awk è potente linguaggio di manipolazione di testi disponibile in ogni sistema Unix. Il suo nome deriva dalle iniziali di Alfred Aho, Peter Weinberger, e Brian Kernighan, che scrissero il programma nel 1977 presso i Bell Labs. Il programma è stato successivamente implementato in diverse versioni. Una molto diffusa e in continuo sviluppo è il gawk del progetto GNU (http://www.gnu.org/s/gawk/). Secondo la definizione data da uno dei sviluppatori, Alfred. V. Aho in una recente intervista
* : AWK è un linguaggio per l’elaborazione di file di testo. Un file viene trattato come una sequenza di record, e per impostazione predefinita, ogni riga è un record che è a sua
volta suddiviso in una sequenza di campi. In questo modo la prima parola in un record
è il primo campo, la seconda, il secondo, e così fino alla fine del record. Un programma
AWK è una sequenza di dichiarazioni del tipo modello-azione. AWK legge l’input una
riga alla volta che viene scansionata confrontandola a ciascun modello definito nel
programma, e ad ogni modello corrisponde una specifica azione che viene eseguita sul
contenuto del record.
Awk può leggere i dati da un file o dallo standard input e scrivere i risultato su un file o come uscita standard sul terminale. Come è stato spiegato da Alfred V. Aho, un file è composto da records ovvero le righe del stesse del documento. Il record è a sua volta composto da campi, che di default sono separati da un numero qualsiasi di spazi o tabulazioni. Il primo campo è memorizzato da una variabile interna chiamata $1, il secondo con $2, e cos via. Nella variable $0 è memorizzato l’intero record.
Ci sono vari modi con cui possiamo eseguire programmi awk. Nel command line or one-line mode viene utilizzato per eseguire una breve programma awk che può essere digitato su una linea di comando.
awk ’programma’ input-file
dove programma consiste di istruzioni incluse tra i due apici. L’uscita può essere reindirizzata in un file come segue:
awk ’program’ input-file > output.xyz
ESEMPIO
Dato un file di input ”coord.xyz” contenente le coordinate in unità Armstrong di due atomi:
C 1.4 1.4 1.7
Il seguente programma legge il file e le converte in nanometri dividendole per 10 e salva il risultato in un nuovo file chiamato ”output.xyz”.
awk ’{print $1, $2/10., $3/10., $4/10.}’ coord.xyz > output.xyz}
Se il file di input (coord.xyz) non è specificato le linee di ingresso devono essere digitate direttamente dal terminale:
<linea di ingresso 1>
<linea di ingresso 2 >
CTRL-c
ESEMPIO
Il programma che segue può essere usato per valutare i valori del potenziale di Lennard-Jones
![V_{LJ}(r)=4\epsilon\left[ \left(\frac{\sigma}{r}\right)^{12}- \left(\frac{\sigma}{r}\right)^6 \right]](https://s0.wp.com/latex.php?latex=V_%7BLJ%7D%28r%29%3D4%5Cepsilon%5Cleft%5B+%5Cleft%28%5Cfrac%7B%5Csigma%7D%7Br%7D%5Cright%29%5E%7B12%7D-+%5Cleft%28%5Cfrac%7B%5Csigma%7D%7Br%7D%5Cright%29%5E6+%5Cright%5D&bg=ffffff&fg=444444&s=0&c=20201002)
dai valori di sigma ($1), epsilon ($2) e la distanza ($3) in ogni riga:
awk ’{print ”sigma: ”,$1, ”epsilon: ”, $2, ”distance: ”, $3, ”VLJ=”,4$2(($1/$3)ˆ12–($1/$3)ˆ6)}’
Si può rendere il programma più comprensibile calcolando le varie parti del potenziale
di LJ e commentandolo.
1 # Le linee che iniziano con # sono considerate commenti
2 # NR e’ una variabile interna del programma awk che contiene il
3 # numero corrente del record letto dal file di input.
4 NR > 0 {
5 # La variabile sr contiene il valore di sigma (in $1) diviso per la distanza (in $3).
6 sr = $1/$3
7 # La variabile sr6 contiene il valore di sr elevato alla potenza di 6.
8 sr6= srˆ6
9 # Per finire, la variabile vlj contiene il potenziale di Lennard–Jones.
10 vlj = 4*$2*(srˆ2–sr6)
11 # Il comando printf e‘ usato per per scrivere i valori di uscita in modo formattato.
12 #
13 printf (”sigma= %12.6f\n Epsilon= %12.6f\n r=%12.6f\n Vvdw=%12.3e\n”,$1, $2, $3, vlj)
14 }
Questo esempio può essere copiato con un editor di testo in un file chiamato, ad esempio ”LJ.awk” ed eseguito in questo modo
awk -f LJ.awk
oppure
awk -f LJ.awk datafile.dat > output.dat
Nel primo caso il programma richiede l’input dal terminale come una sequenza di tre numeri (sigma, epsilon, distanza) seguito dal comando Ctrl-d. L’output viene quindi stampato sul terminale. Nel secondo caso, l’ingresso è dato dal file chiamato ”datafile.dat” e l’output è scritto nel file ”output.dat”.
In questo esempio,la variabile interna NR è usata per identificare il numero della linea. Awk ha altre variabili interne con funzioni specifiche. Altre variabili molto utili sono NF che mantiene un conteggio del numero di parole in una linea di ingresso.
L’ultimo campo la linea di ingresso pu essere designato da $NF. FILENAME che contiene il nome del file corrente e, infine, FS che contiene il carattere separatore di campo. Il valore predefinito sono i caratteri di spazio o di tabulazione. Il valore di FS può essere riassegnato ad un altro carattere per modificare il separatore di campo. Nell’esempio abbiamo usato anche il comando printf per la stampa formattato delle informazioni di uscita. Il codice di formattazione ha il formato: % nn.mmT dove nn indica il numero totale di numeri / caratteri ed mm il numero di cifre che rappresenta la parte decimale dell’esponente, T indica i codici di formato:
- d: Stampa un numero in formato decimale.
- o: ” un numero in formato ottale.
- x: ” un numero in formato esadecimale.
- c: ” un carattere, dato il suo codice numerico.
- s: ” una stringa.
- e: ” un numero in formato esponenziale.
- f: ” un numero in formato a virgola mobile.
- g: ” un numero in formato esponenziale o in virgola mobile.
Il simbolo dopo il carattere backslash (\) sono codici per il controllo del carrello di stampa:
- \n: nuova riga (line feed).
- \t: scheda orizzontale.
- \b: backspace.
- \r: ritorno carrello.
- \f: Avanzamento carrello.
Come rendere lo script awk autoeseguibile
Il file contenente il precedente programma può essere reso eseguibile come un normale
programma Unix aggiungendo questa riga all’inizio del file:
#!/bin/awk -f
Dopo aver salvato il file, per renderlo eseguibile si usa il seguente comando
chmod + x LJ.awk
A questo punto, il programma può essere eseguito semplicemente digitando:
./LJ.awk
oppure
./LJ.awk datafile.dat > output.dat
Struttura del linguaggio Awk
Un programma awk è una sequenza di dichiarazioni del modulo:
<search pattern 1> {<program actions>}
<search pattern 2> {<program actions>}
…
END {<final actions>}
La clausola BEGIN contiene un blocco di linee di codice che viene eseguito prima della scansione del file di input. Il blocco BEGIN può anche essere usato per scrivere un programma awk che non richieda la scansione di un file. Le linee < ricerca di pattern > contengono espressioni aritmetiche, alfanumeriche o booleane che definiscono un criterio di ricerca che viene usato per selezionare le informazioni dal file di input sulle quali viene eseguita l’operazione descritta nelle parentesi graffe che seguono. Le operazioni sono una sequenza di istruzioni terminata da una nuova righe o da punti e virgola. Infine, la clausola finale END può essere utilizzata per eseguire elaborazioni di dati letti dal file di dati di input. Ad esempio, si può effettuare una elaborazione statistica dei dati estratti dal file di input.
Il linguaggio Awk prende molto in prestito dal linguaggio C. La condizioni controllo if-else e while, il ciclo for hanno la stessa sintassi di quelli in C. Esistono comunque differenze sostanziali nella definizione delle variabili. Infatti, l’assegnazione del tipo di variabile è contestuale: il programma stabilisce se la variabile è numerica o di stringa dal tipo di caratteri assegnati. Operazioni sul variabili di tipo alfanumerico darà come risultato una variabile alfanumerica e lo stesso avviene con variabili numeriche. Per esempio questo programma assegna un valore di stringa alla variabile ”x”, questa viene quindi trattata come stringa nell’assegnazione del valore alla variabile ”y” poichè viene combinata con la stringa di testo ”volte”. Mentre se viene incrementata dal valore numerico 0.5, la stringa ”3” verrà convertita in un valore numerico e incrementato di 0.5.
Per confrontare valori numerici si usano gli stessi operatori di confronto usati nel linguaggio C, quali “==”, “<“, “>”, “<=”, “>=”, “!=”. Per caratteri o stringhe di testo si usano gli operatori “ “, “! “. Gli ultimi due operatori controllano se i due valori ”corrispondono” o ”non corrispondono”, rispettivamente. Gli operatori aritmetici sono glib usuali +,– ,/,*,% e, ^ per l’elevamento a potenza. Sono anche disponibili operatori unari presenti nel linguaggio C come ++, –, += , –=, /= . Nell’ esempio che segue viene mostrato un esempio di uso di questi operatori. Provate a indovinare il punto finale nel piano (x,y) dove vi porta il programma ! . Il carattere # indica l’inizio di un commento e può essere inserito come linea separata o alla fine di un comando.
2 x = 1; y=1
3 x++ # incrementa x di uno
4 y–– # decremento y di uno
5 x+=10 # incrementa x di 10
6 x–– # decrementa x di 1
7 x–=7 # decrementa x di 7
8 x/=2 # divide per 2 il valore x
9 x*=10 # moltiplica per 10 il valore di x
10 x=xˆ2 # eleva a potenza il valore di x
11 y+=7
12 y++
13 y/=1
14 print x,1
15 }
Il linguaggio awk dispone di variabili array per la memorizzazione stringhe o numeri. Gli array in awk sono associativi ovvero ogni array è un insieme di coppie: un indice e il valore del suo elemento.
Per la descrizione della sintassi delle istruzioni del linguaggio awk si farà uso di esempi pratici in cui verranno usati i vari costrutti disponibili nel linguaggio. Per un ulteriore approfondimento, Il lettore è vivamente incoraggiato a consultare la manualistica riportata alla fine dell’appendice.
Comandi per cicli iterativi
Questo primo programma contiene un esempio di utilizzo del ciclo for () {…}.
ESEMPIO 1
Questo programma è una estensione di quello dato nell’introduzione per il calcolo della funzione di Lennard-Jones per dati valori di σ (sig), ϵ (eps) e nell’intervallo (ri – rf) con incrementi di δx. Il programma non usa un input file e pertanto è stato scritto interamente nel blocco BEGIN. All’ inizio si definiscono i valori delle variabili σ e ϵ della funzione e l’intervallo della distanza da calcolare.
1#
2# Calculate the LJ function for a range of distances
3#
4 BEGIN {
5
6 # Assign the LJ parameters to calculate the function sigma
7 sig = 2.0
8
9 # and epsilon
10 eps = 0.1
11
12# Assign the starting value of distance,
13 ri=1
14
15 # the final value of the distance
16 rf=20
17
18 # and the distance increment
19 dx=0.2
Le successive istruzioni servono per stampare i valori. Ogni valore viene stampato
con il carattere # all’inizio. Il motivo verrà spiegato successivamente.
2 printf (”# Distance internal ri=%12.6f –– rf=%12.3f\n”,xi, xf)
3 printf (”# Distance Increment: %12.6f\n”,dx)
In questa parte di codice viene eseguito il ciclo for () {}, che inizia dal valore r = ri e continua fino a quando la condizione r <= rf non è verificata. Le distanze vengono incrementate di dr con il comando r+= dr. Pertanto vengono calcolati nd = (rf – ri)∕dr values.
2# sr variable contain the value of sigma/distance
3 sr = sig/r
4# the variable sr6 contain sr power 6
5 sr6= srˆ6
6# vdw contain the value of the Lennard Jones potential
7 vlj = 4*eps*(srˆ2–sr6)
8# the command printf is used for the formatted printing of the
9# distance and LJ potential
10 printf ( r=%12.6f\n %12.3e\n”,r, vlj)
11 }
12 }
Eseguire il programma dalla linea di comando della shell dirigendo l’uscita in un
file: awk -f example1.awk > output.dat
La curva di LJ tabulata nel file (output.dat) può essere visualizzata usando il
programma xmgrace:
xmgrace output.dat
questo è un programma di pubblico dominio che può essere usato per creare grafici bidimensionali. Le linee di dati nella file che iniziano con ”#” vengono considerate commenti e non utilizzate. Un altro programma molto potente per la rappresentazionedi dati anche in 3D è il gnuplot.
| Esercizio 1) Utilizzare il valore indicato nella tabella sottostante per calcolare la curva di LJ per Ar, Kr e Xe. I valori di ϵ sono espressi in Kelvin poichè sono divisi per la costante di Boltzmann (k).
2) Modificare il programma per calcolare la funzione di energia potenziale del tipo
|
||||||||||||||||||||||||||||||
 /nm
/nm /K
/K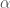
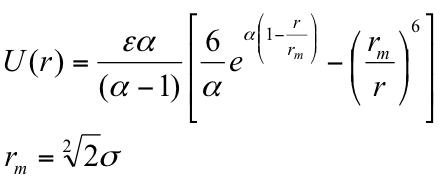
ESEMPIO 2
In questo esempio vedremo come si leggono dei dati da un file e si calcolano, nel blocco END, la loro media e la varianza utilizzando la formula approssimata:

I dati sono dei numeri casuali generati dal generatore interno rand usando il seguente programma di supporto. Il generatore viene inizializzato dal commando stand(n) con n un intero in questo caso 12239. Il ciclo genera n = 100 numeri casuali nell’intervallo 0 – 100.
2#
3 BEGIN {
4#
5# srand ([x]) where [x]is an integer number, initialize the
6# random number generator. Awk generate the same sequence of
7# pseudo random number for each value of [x].
8#
9 srand(12239)
10#
11# n is the number of number to be generated
12#
13 n=100
14#
15# from loop from 1 to n
16# int(n*rand()) generate a random number between 0 and n.
17#
18 for (k=1;k<=n;k++) {
19 printf (”%5d %8.3f\n”,k,int(n*rand()))
20 }
21 }
Copiate il programma in un file chiamato rand.awk ed eseguitelo redirizionando
l’uscita su un file (datafile.dat):
awk -f rand.awk > datafile.dat
Il programma che segue calcola le medie e la varianza dei dati presenti nel file
datafile.dat usando la formula 2.4.
1# PROGRAMMA PER IL CALCOLO DELLA STATISTICA
2# The variable cc is used to count the number of data.
3# The data to be elaborated in the file are organized in columns.
4# In data the values in the second column is temporary
5# stored
6#
7
8NR > 0 {
9 data=$2
10 cc += 1
11 sum += data
12 sum2 += (data*data)
13}
14 END {
15 print ”#––––––––––––––––––––––––––––––––––––––––––––”
16 m = sum/cc
17 m2 = sum2/cc
18 s2 = m2 – m*m
19 printf ”#Average : %4f\n”, m
20 printf ”#Variance : %3e\n”, s2
21 print ”#––––––––––––––––––––––––––––––––––––––––––––”
22 }
Per eseguirlo copiare il programma in file (es. statistica.awk) ed eseguirlo dalla
linea di comando come segue:
awk -f statistica.awk datafile.dat
ESERCIZI
- Modificare l’esempio per calcolare e stampare anche la deviazione standard
dei dati. - Modificare il seme iniziale di srand () nel programma rand.awk, ed eseguirlo
nuovamente. - La media incrementale (running average in inglese) è utilizzata per verificare la convergenza al colore medio di un set di dati. Essa viene calcolata per ogni valore della lista dei dati come valore medio dei valori precedenti. L’ultimo valore medio corrisponde alla media totale del set di dati. Visualizzando la curva, è facile valutare la convergenza a valore costante della media dei dati. Questo tipo di analisi è molto utile nello studio delle serie temporali generate da programmi di DM. Provare a modificare il codice nella prima sezione del programma per calcolare e stampare la media incrementale per ogni dato letto in ingresso.
ESEMPIO 3
Questo è un esempio più complesso dei precedenti ma molto utile per capire altri comandi del linguaggio awk.
Il programma legge le coordinate x,y,z di una molecola in formato xyz e di seguito una lista di coppie di numeri che definiscono i legami tra gli atomi della molecola. Questi dati sono memorizzati in arrays e sono utilizzati per calcolare le distanze di legame. Anche in questo caso il programma è tutto scritto nel blocco BEGIN
2# CALCOLA LE DISTANZE DI LEGAME
3# DALLE COORDINATE E LISTA DI LEGAMI
4# DI UNA MOLECOLA
5#
6BEGIN {
7# Initialize variables
8 cc=0
9 bb = 0
10
11# Read the number of atoms
12# getline is function that force the program to read one line from
13# the input file
14#
15 getline
16 natom = $1
17# read title line
18 getline
In questa prima parte vengono inizializzate alcune variabili e vengono lette le prime due linee del file di coordinate che contengono rispettivamente il numero di atomi e un titolo. Il resto del file viene letto usando il comando condizionale while(condizione). In questo caso le istruzione nelle parentesi graffe sono eseguite fino a quando il commando getline da un risultato vero ovvero legge un linea dal file. Alla fine del file il commando ritorna 0 che termina il ciclo. Nel ciclo viene controllata ogni linea del file di input che contenga almeno un campo (NF>0), viene quindi controllato se il primo carattere della linea sia un carattere con in comando substr($1, 1, 1). Questo mando estrae dal primo campo la prima lettera e la confronta con le lettere maiuscole e minuscole dell’alfabeto usando l’operatore di confronto e l’espressione regolare ∕[A – Z,a – z]∕. Se la condizione è verificata vengono letti campi e assegnati a variabili che contengono il nome dell’atomo, il numero di sequenza e le coordinate x,y,z.
2 while (getline) {
3#
4# The if condition check if the condition in the argument in
5# parenthesis is true to execute the command in the curl
6# parenthesis. In this case it check if the NF of field in the
7# line is large of zero namely if the line is not empty.
8#
9 if (NF > 0) {
10#
11# The substr(var,pos,num) is a command to extract data
12# from a strings of characters in a variable (var). The extracted
13# string begin from the position ?pos? of the original string
14# until position (pos+num). In this case the first char–acter of
15# the string is extracted and compared (˜) with the alphabetical
16# character. /[A–Z,a–z]/ is a regular expression, a meta–command
17# for complex.
18#
19 if (substr($1,1,1) ˜ /[A–Z,a–z]/) {
20#
21# Read from the coordinate lines the following information in the
22# indicated arrays.
23# name of the atom ––> aname[]
24# atom number ––> anum[]
25# x,y,z coordinates ––> x[],y[],z[]
26# the index cc count the atoms and address the corresponding
27# elements of the arrays to store the information of all the atoms.
28#
29 aname[cc]=$1
30 anum[cc]=$2
31 x[cc]=$3
32 y[cc]=$4
33 z[cc]=$5
34 cc++
35 } else {
36 bond[bb,0]=$1
37 bond[bb,1]=$2
38 bb++
39 }
40 }
41 }
42#
43# Calculate the distance
44#
45 for (i=0;i<=bb;i++) {
46 ii=bond[I,0]
47 jj=bond[I,1]
48 d2=(x[i]–x[j])ˆ2+(y[i]–y[j])ˆ2+(z[i]–z[j])ˆ2
49 d=sqrt(d2)
50 printf (”%3d %3d : %8.3f\n”,ii,jj,d)
51 }
52} # End Begin
Copiate il programma in un file chiamato exemple3.awk e utilizzate le seguenti coordinate atomiche della urea per provare il programma.
|
|
|
8 Title: Urea C 1 20.64 21.62 2.80 O 2 21.63 21.20 3.39 N 3 20.55 22.85 2.29 H 4 19.65 23.01 1.88 H 5 21.36 23.42 2.12 N 6 19.51 20.93 2.85 H 7 18.66 21.25 2.44 H 8 19.58 19.99 3.20 |
|

Copiate le coordinate in un file (Urea.xyz) e aggiungere alla fine di questo la lista dei legami della molecola in seguente formato.
1 2
…
Quindi eseguire il programma come segue:
awk -f example3.awk Urea.xyz
Modificare il programma per calcolare gli angoli di legame data la loro lista.
ESEMPIO 4
Questo esempio mostra come estrarre da un file di uscita (.log) del programma Gaussian, il profilo di energia in funzione dell’angolo (vedi Capitolo II).
2BEGIN {
3# Incremento in gradi della scansione
4 step = 10.
5# Fattore di conversione Hartree ––> Kcal/mol
6 conv = 627.5095
7 cc = 0
8 count = 0
9 }
10$1 == ”EIGENVALUES” { for (i=3;i<=NF;i++) {
11 k=split($i,a,”–”)
12 for (ii=1;ii<=k;ii++) {
13 if (a[ii] != ””) {
14 val = –a[ii]
15 en[cc] = val
16 if (val < min) {min = val}
17 count+=step
18 cc++
19 }
20 }
21 }
22 }
23END {
24 count = 0
25 for (ii=0;ii<cc;ii++) {
26 printf ”% 4.1f %8.3f\n”, count, (en[ii]–min)*conv
27 count+=step
28 }
29 }
Nota finale
Altri linguaggi di scripting sono stati sviluppati e ispirati dal programma awk. Due linguaggi di scripting comunemente usati sono il Perle il Python. Una descrizione in queste pagine di questi linguaggi sarebbe troppo lunga, tuttavia esiste una copiosa letteratura e video tutorials gratuitamente disponibile sul internet. Se si desidera avere un rapido assaggio del linguaggio Perl si possono convertire i programmi awk di questo tutorial in perl usando il comando:
a2p program.awk > program.pl
ed eseguire il relativo programma perl digitando
perl program.pl
BIBLIOGRAFIA
- Shelley Powers, Jerry Peek, Tim O’Reilly ,Mike Loukides. Unix Power
Tools. O’Reilly Media, Inc .; 3a edizione. (1 ottobre 2002) - Alfred V. Aho, Brian W. Kernighan, Peter J. Weinberger. AWK
Programming Language.

