Awk is a powerful Unix tool. Its name derives from the surname initials of Alfred Aho, Peter Weinberger, and Brian Kernighan who originally designed it at Bell Labs in 1977. The program has a different version and implementations. A commonly used one is the gawk from the GNU (http://www.gnu.org/s/gawk/). According to the definition of one of its developer, Alfred. V. Aho: “AWK is a language for processing files of text. A file is treated as a sequence of records, and, by default, each line is a record. Each line is broken up into a sequence of fields so we can think of the first word in a line as the first field, the second word as the second field, and so on. An AWK program is a sequence of pattern-action statements. AWK reads the input a line at a time. A line is scanned for each pattern in the program, and for each pattern that matches, the associated action is executed.”
Awk can read data from a file or from its standard input, and outputs to its standard output. A file consists of records, which by default are the lines of the file itself. A record consists of fields, which by default are separated by any number of spaces or tabs. Field number 1 is accessed by a built-in variable named $1, field 2 with $2, and so forth. $0 refers to the whole record.
There are four ways in which we can run awk programs
One-liner: it is used to run a short one-use-only awk program.
awk ‘program‘ input-file
where program consists of a series of patterns and actions (note, the quotes ‘…’ must enclose the program body). The output can be redirected to a file as follows:
awk ‘program‘ input-file > output.xyz
Example:
Given the input file “coord.xyz” containing the coordinates in Armstrong of two atoms:
C 4.3 4.5 5.6
C 1.4 1.4 1.7
The one-line awk program read the file and converts the coordinates in nanometer by dividing them by 10.
awk ‘{print $1, $2/10., $3/10., $4/10.}‘ coord.xyz > output.xyz
If the input file is not specified the input lines can be typed directly from the terminal:
awk ‘program‘ <ENTER>
<input lines>
<input lines>
# press CTRL key + c to stop
Example:
This program can be used to evaluate the values of the Lennard-Jones function giving the values of sigma ($1), epsilon ($2) and di
There are four ways in which we can run awk programs
One-line: it is used to run a short one-use-only awk program.
awk ‘program‘ input-file
where program consists of a series of patterns and actions (note, the quotes ‘…’ must enclose the program body). The output can be redirected on a file as follows:
awk ‘program‘ input-file > output.xyz
Example:
Given the input file “coord.xyz” containing the coordinates in Armstrong of two atoms:
C 4.3 4.5 5.6
C 1.4 1.4 1.7
The one-line awk program read the file and converts the coordinates in nanometer by dividing them by 10.
awk ‘{print $1, $2/10., $3/10., $4/10.}‘ coord.xyz > output.xyz
If the input file is not specified the input lines can be typed directly from the terminal:
awk ‘program‘ <ENTER>
<input lines>
<input lines>
ctrl-c
Example:
This program can be used to evaluate the values of the Lennard-Jones function giving the values of sigma ($1), epsilon ($2) and distance ($3) in each line:
awk ‘{print $1, $2, $3, “VLJ=”,4$2(($1/$3)^12-($1/$3)^6)}‘
For longer and complex program it is possible to write the instructions in a source file and run it in this way:
awk -f source-file input-file1 input-file2 …
Example:
# line starting with # are comment lines
# NR is a&nbsp;build-in&nbsp;variable of awk and it keeps a current count of the number of input lines.
NR > 0 {
# sr variable contain the value of sigma/distance
sr = $1/$3
# the variable sr6 contain sr power 6
sr6= sr^6
# vlj contain the value of the Lennard Jones potential
vlj = 4*$2*(sr^2-sr6)
# the command printf is used for the formatted printing of the results
printf (sigma= %12.6f\n Epsilon= %12.6f\n r=%12.6f\n Vvdw=%12.3e\n”,$1, $2, $3, vlj)
}
This example can be copied with a file editor in a source file called for example “lj.awk” and executed as:
awk -f LJ.awk
or
awk -f LJ.awk datafile.dat > output.dat
In the first case, the program will get the input from the terminal as a sequence of three numbers (sigma, epsilon, distance) followed by entering until the command ctrl-d. The output is written on the terminal screen. In the second case, the input is given from the file datafile.dat and the output is written in the file output.dat.
In this example, the built-in variable NR is used to identify the line number. Awk has other built-in variables with specific functions. Three useful examples are:
NF: Keeps a count of the number of words in an input line. The last field in the input line can be designated by $NF.
FILENAME: Contains the name of the current input file.
FS: Contains the field separator character. The default is “white space”, meaning space and tab characters. FS can be reassigned to another character to change the field separator.
Example:
In the example, we have also used the command printf for the formatted printing of the output information. The formatting code has the format: %nn.mmT where nn indicate the total number of numbers/characters and mm the number of digits representing the decimal part of the exponent, T indicate the format codes:
d: Prints a number in decimal format.
o: Prints a number in octal format.
x: Prints a number in hexadecimal format.
C: Prints a character, given its numeric code.
s: Prints a string.
e: Prints a number in exponential format.
f: Prints a number in floating-point format.
g Prints a number in exponential or floating-point format.
The symbol after the backslash () character are escape codes:
\n: Newline (line feed).
\t: Horizontal tab.
\b: Backspace.
\r: Carriage return.
\f: Form feed.
Self-executing awk programs
This source file of the previous example can be made self-executing by adding this the first line:
#! /bin/awk -f
Saving the file and making it executable with the following command
chmod +x LJ.awk
The program can be run simply typing it:
./LJ.awk
or
./LJ.awk datafile.dat output.dat
AWK LANGUAGE STRUCTURE
An awk program is a sequence of statements of the form:
BEGIN {<initializations>}
<search pattern 1> {<program actions>}
<search pattern 2> {<program actions>}
…
END {<final actions>}
The BEGIN clause performs any initializations required before Awk starts scanning the input file. The BEGIN {} clause can be used alone to write the entire awk program. The < search pattern > statements in front of an action can be a regular expression, arithmetic relational expressions, string-valued expressions, and arbitrary boolean combinations of these. It is used to select from the input data information that determines whether the action is to be executed. Program actions are a sequence of action statements terminated by newlines or semicolons. These action statements can be used to do a variety of bookkeeping and string manipulating tasks. The END clause can be used to perform any final actions required. For example, it can make a statistics elaboration of the data extracted from an input file.
The syntax of Awk borrows a lot from the C language. The if condition, for loop and while loop has the same constructs as in C. Awk’s variables are stored internally as strings. Variables have no data type, and can be used to store either string or numeric values; string operations on variables will give a string result and numeric operations will give a numeric result, with a text string that doesn’t look like a number simply being regarded as 0 in a numeric operation.
BEGIN {
x = “3”
y=x “times”
x = x + 0.5
print x,y
}
Copy the program in a file named test.awk and run it with the command:
awk –f test.awk
This program will print the value 3.5 and the world 3times.
Comparison operators in awk are : “==”, “<“, “>”, “<=”, “>=”, “!=“, “!~“. “~”. The last two operators check for “matches” and “does not match”. Common arithmetic operators in awk are : “+”, “-“, “/”, “*“; “^” is the exponentiation operator. “%” is the modulo operator. All the C operators like “++”, “–”, “+=“, “-=”, “/=“ etc. are also valid.
The awk language use one-dimensional arrays for storing groups of related strings or numbers. Arrays in awk are associative. This means that each array is a collection of pairs: an index, and its corresponding array element value. In the following examples, different awk’ commands are used and explained. More examples and detailed information can be obtained from the official gnu user guide and the numerous online tutorials.
EXAMPLE 1
This program calculate the LJ function
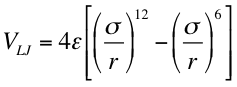
for given values of sigma (sig), epsilon (eps) and in the interval (xi:xf) with increments of dx. This program contains an example of the use the loop statement for () { …} .
#
# Calculate the LJ function for a range of distances
#
BEGIN {
# Define the parameters to calculate the function
# sigma
sig = 2.0
# epsilon
eps = 0.1
# Starting value of distance
xi=1
# Final value of the distance
xf=20
# distance increment
dx=0.2
# for loop on the distance range from xi to xf with incremental
# distance dx the argument in the parenthesis define for the distance
# variable x the # initial value (x=xi) the #condition to check to
# evaluate when the cycle must terminate (x<=xf; e.g. the value of x
# should be not larger than xf) and the incremental operation on x
# (x+=dx à x=x+dx) that is done for each cycle.
# Therefore, the number of distances calculate by the cycle is equal
# to nd=(xf-xi)/dx.
# The command printf is used for the formatted printing of the input data
printf (“# sigma= %12.6f\n #Epsilon= %12.6f\n”,sig,eps)
printf ( “Initial r=%12.6f\n Final r=%12.3f\n Distance Increment: %12.6f”,xi, xf, dx)
for (x=xi;x<=xf;x+=dx) {
# sr variable contain the value of sigma/distance
sr = sig/x
# the variable sr6 contain sr power 6
sr6= sr^6
# vdw contain the value of the Lennard Jones potential
vlj = 4*eps*(sr^2-sr6)
# the command printf is used for the formatted printing of the distance
# and LJ potential
printf ( “%12.6f\n %12.3e\n”,x, vlj)
}
}
Run the program
awk –f example1.awk > output.dat
The curve in the output.dat file can be visualized using an excel datasheet or using the command:
xmgrace output.dat
EXERCISES
- Using the value in the Table below plot the Lennard Jones curve for Ar, Kr and Xe. Note that the values of epsilon are divided by the Boltzmann constant and therefore expressed as a temperature (Kelvin).
|
| Lennard-Jones Potential |
Exp-6 potential | |||
|
Substance |  /nm /nm |  /K /K |  | /nm | //K |
| Ar | 0.3336 | 141.2 | 18 | 0.3302 | 152.0 |
| Kr | 0.3575 | 191.4 | 18 | 0.3551 | 213.9 |
| Xe | 0.3924 | 257.4 | 22 | 0.3823 |
326.0 |
2) Modify the program to calculate the curve for the Exp-6 potential energy function:

EXAMPLE 2
This program reads a set of data in a file and, in the END clause, it calculates its average and variance using the following formula:
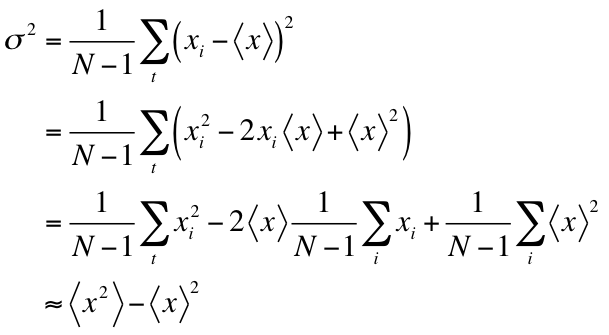
#
# The variable cc is used to count the number of data.
# The data to be elaborated in the file are organized in columns.
# In data the values in the second column is temporary
# stored
NR > 0 {
data=$2
cc += 1
sum += data
sum2 += (data*data)
}
END{
print "#--------------------------------------------"
m = sum/cc
m2 = sum2/cc
s2 = m2 - m*m
printf "#Average : %4f\n", m
printf "#Variance : %3e\n", s2
print "#--------------------------------------------"
}
1) Copy the program in a file name example2.awk.
2) Generate two columns random data file using the following program:
BEGIN {
# srand ([x]) where [x]is an integer number, initialize the
# random number generator. Awk generate the same sequence of
# pseudo random number for each value of [x].
srand(12239)
# n is the number of number to be generated
n=100
# from loo from 1 to n
for (k=1;k<=n;k++) {
# int(n*rand()) generate a random number between 0 and n-1.
printf ("%5d %8.3f\n",k,int(n*rand()))
}
}
3) Copy the program in a file named rand.awk and run as:
awk –f rand.awk > datafile.dat
4) run the exercise as:
awk –f exercise2.awk datafile.dat
EXERCISES
- Modify the example to calculate and print the standard deviation of the data.
- Change the initial seed in srand () of the program rand.awk, and run again the
- The running average is used to check the trend of the average in a set of data. It is calculated and printed at each input data point as the average value of the previous points (running average). The last point corresponds to the total average of the data set. By visualizing the curve, it is easy to estimate the convergence to a plateau of the average value.
Try to add the line of code in the first section of the program to calculate and print the running average.
EXAMPLE 3
This is a more complex in which other programming features of awk are reported. The program read a set of coordinate in xyz format followed by the atom-bond connectivity. These data are stored in arrays and used to calculate the bond distances.
BEGIN {
# Initialize some variables
cc=0
bb = 0
# Read the number of atoms
# getline is function that force the program to read one line from
# the input file
#
getline
natom = $1
# read title line
getline
#
# The while () {..} conditional statement is used to read the rest of the# file untile the end.
# The instruction inside the curled bracket are executed until the
# command getline can result an true # value (=success in reading
# a line). At the end of file the getline return a false and the
# program continue to the next instruction of the program
while (getline) {
#
# The if condition check if the condition in the argument in
# parenthesis is true to execute the command in the curl parenthesis.
# In this case it check if the NF of field in the line is large of zero
# namely if the line is not empty.
if (NF > 0) {
# The substr(var,pos,num) is a command to extract data from a strings
# of characters in a variable (var). The extracted string begin from
# the position “pos” of the original string until position (pos+num).
# In this case the first character of the string is extracted and
# compared (~) with the alphabetical character. /[A-Z,a-z]/ is a
# regular expression, a meta-command for complex
if (substr($1,1,1) ~ /[A-Z,a-z]/) {
#
# Read from the coordinate lines the following information in the
# indicated arrays.
# name of the atom -> aname[]
# atom number -> anum[]
# x,y,z coordinates -> x[],y[],z[]
# the index cc count the atoms and address the corresponding
# elements of the arrays to store the information of all the atoms.
aname[cc]=$1
anum[cc]=$2
x[cc]=$3
y[cc]=$4
z[cc]=$5
cc++
} else {
bond[bb,0]=$1
bond[bb,1]=$2
bb++ }
}
}
#
# Calculate the distance
#
for (i=0;i<=bb;i++) {
ii=bond[I,0]
jj=bond[I,1]
d2=(x[i]-x[j])^2+(y[i]-y[j])^2+(z[i]-z[j])^2
d=sqrt(d2)
printf (“%3d %3d : %8.3f\n”,ii,jj,d)
}
} # End Begin
Copy the program in a file named exemple3.awk
Use for the program the following atomic coordinated of the Urea in xyz format:
8 Title: Urea C 1 20.64 21.62 2.80 O 2 21.63 21.20 3.39 N 3 20.55 22.85 2.29 H 4 19.65 23.01 1.88 H 5 21.36 23.42 2.12 N 6 19.51 20.93 2.85 H 7 18.66 21.25 2.44 H 8 19.58 19.99 3.20 | 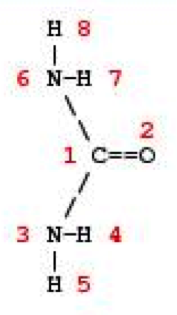 |
Copy the coordinate in a file (eg. Urea.xyz), and add at the end of the file the bond topology in the format:
12 …
Run the program
awk –f example3.awk Urea.xyz
EXERCISE
Modify the program to calculate the bond angles given the bond connectivity.
FINAL NOTE
Other scripting languages have been developed inspired to the awk program. One commonly used scripting language is the Perl. A copiously amount of literature and tutorials on this language are freely available on web. If you want to have a quick taste of this language, try to convert the awk programs of this tutorial to Perl using the command:
a2p program.awk > program.pl
and execute the corresponding perl program using
perl program.pl


Pingback: Retro programming nostalgia III: the MSX Microcomputer and the Orbit of the Planets in the Solar System | Danilo Roccatano
Pingback: Physical Chemistry: The Simple Hückel Method (Part II) | Danilo Roccatano
Pingback: Programming in Awk Language. LiStaLiA: Little Statistics Library in Awk. Part II |