Difficilmente è vinto colui che sa conoscere le forze sue e quelle del nemico.
Nicollò Machiavelli in Dell’arte della guerra (1519-1520)
Un virus è la vita nella forma più semplice. È la riduzione minimalista di un organismo ai suoi elementi essenziali di funzionalità. Più pragmaticamente, un virus è un contenitore di codice genetico dotato di un efficiente meccanismo molecolare che gli consente d’invadere una cellula ospite di un organismo capace di riprodursi autonomamente. Come macchina molecolare, un virus può assomigliare nella forma e potere distruttivo, alla Morte Nera della saga di Star Wars. Pertanto, è un tipo di macchina molecolare che non vogliamo assolutamente avere dentro di noi!
La diffusione del coronavirus SARS-CoV-2 (COVID-19) ha prodotto una nuova pandemia, ovvero una infezione causata da un agente patogeno che colpisce l’intera popolazione di una specie vivente, in questo caso quella umana. Questa situazione di emergenza globale è il risultato di una competizione naturale tra specie viventi che ci rammenta di essere ancora un tassello nell’ecosistema di Gaia. Tuttavia, anche se sia sempre arduo da credere visto lo stato in cui abbiamo ridotto il nostro pianeta, siamo la forma di vita più intelligente nell’universo conosciuto. Quindi sarebbe abbastanza imbarazzante essere sconfitti da un nemico invisibile.
Come suggerisce Machiavelli, il modo migliore per sconfiggere il nemico è comprendere sia lui che noi stessi. Questa epica guerra naturale mi ha spinto a iniziare questo blog dove condividerò ciò che sto imparando su questa pericolosa macchina molecolare.
Il coronavirus è un gruppo di virus zoonotici che infettano mammiferi e uccelli che hanno sviluppato, strategicamente, un alto tasso di mutabilità per sopravvivere alle difese immunitarie degli organismi ospiti. Entrano nell’ ospite attraverso i tessuti delle vie aeree e, quindi, sono facilmente trasmessi. L’elevata mutabilità del materiale genetico di questo tipo di virus, la somiglianza del sistema immunitario delle specie infestate (quali maiali, topi, pipistrelli, cammelli o uccelli) e i loro stretti contatti con l’uomo, hanno determinato (e, in alcune occasioni in un tempo più breve della durata media della vita umana) la cosiddetta trasmissione di salti interspecie. In questo caso il nuovo virus è diventato una nuova pericolosa minaccia per la specie umana. Verso la fine di novembre 2019, nel mercato degli animali e dei frutti di mare nella città di Wuhan (Cina) si è verificato questo salto tra un animale malato, non ancora identificato, e il suo venditore e /o compratore. Ufficialmente, questo segnò l’inizio della diffusione di una nuova specie di coronavirus potenzialmente letale per l’uomo. Non è ancora chiaro la specie di animale che ha trasmesso il virus all’uomo. I pipistrelli sono tra i candidati, ma studi più recenti suggeriscono anche i pangolini.
Un virus che diventa ospite di un’altra specie può essere molto pericoloso per quest’ultima. Infatti, negli animali, originari portatori del virus, la selezione naturale ha adattato le difese immunitarie per far fronte alla invasione del virus. In modo simile a quello con cui il nostro sistema immunitario riesce a contrastare la comune influenza. Al contrario, il sistema immunitario della nuova specie ospite può non accorgersi dell’invasore, rispondendo troppo lentamente, o produrre una risposta eccessiva alla infezione del nuovo virus. In quest’ultimo caso, il meccanismo di difesa immunitario stesso diventa la causa del pericolo. Quest’ultima situazione sembra essere una delle cause principale che rende il COVID-19 un pericolo mortale. Molti di noi, in particolare quelli più vulnerabili poiché affetti da complicanze legate all’età, o con un sistema respiratorio compromesso, sono sopraffatti dalla controffensiva delle difese immunitarie che invece di salvarli finisce per farli annegare. Gran parte del bilancio delle vittime di COVID-19 è la triste conseguenza di questo effetto.
Per cercare di capire al livello molecolare quello che succede devo riassumere quello che si conosce sula struttura di questa complessa macchina da guerra nanoscopica e sul suo meccnismo di invasione e riproduzione nel suoi ospiti.
Il ciclo di vita di un virus comprende più o meno le seguenti fasi.
- Il virus entra nel nostro corpo, principalmente attraverso le vie respiratorie. Per questo motivo è importate proteggersi dall’infezione usando mascherine adatte e con una igiene accurata delle mani. Una volta entrato nei bronchi, il virus cerca una via di entrata nelle cellule del tessuto epiteliali che copre la superficie interna delle nostre vie respiratorie. In particolare, il virus si lega a delle proteine di membrana (recettori) che protrudono dalle cellule epiteliali e che hanno funzioni di varie tipo.
- Con un meccanismo molecolare complesso, il virus penetra nella cellula, fondendo il suo involucro lipidico con la membrana cellulare.
- L’acido nucleico (RNA a singola catena per il COVID-19) liberato dal suo rivestimento proteico (il capsomero costituito da proteine nucleocapsidiche) è pronto per essere letto dal meccanismo di espressione della cellula ospite.
- Normalmente in questa fase viene espressa solo la parte iniziale della catena di RNA virale che contiene l’armamentario proteico responsabile alle funzioni genetiche, quali la replicazione del cromosoma virale. In alcuni virus, questo armamentario comprende anche proteine usate per disattivare la funzione della cellula ospite e, quindi, massimizzare quindi le risorse disponibili per la propria riproduzione.
- Il virus produce centinaia di copie del suo materiale genetico. In questa fase, il virus inizia a produrre la proteina strutturale per il capsomero e altre proteine incorporate nella membrana lipidica virale.
- Le proteine nucleocapside si riuniscono attorno all’RNA del virus formando il capsomero.
- Le tre proteine strutturali del virus vengono esposte sulla superficie esterna della membrana della cellula ospite.
- Il capsomero viene infine rilasciato dalla cellula per esocitosi rivestendolo con un pezzo di membrana cellulare popolato con proteine virali.
Nell’ appendice di questo articolo, ho riportato una lista di link a bellissime animazioni che riassumono visivamente tutto il processo.
Per meglio comprendere i dettagli di ogni fase di questo complesso processo molecolare, dobbiamo analizzare in dettaglio quello che si conosce sulla struttura e la funzione di un coronavirus.
In generale, i virus sono particelle con dimensioni che vanno da 0.02 a 0.25 micrometri (

In generale, i virus sono classificati a seconda del tipo di materiale genetico che trasportano come specie contenenti DNA o RNA. La differenza determina anche il tipo di meccanismo che sfruttano per riprodursi una volta all’interno della cellula ospite. Virus con RNA o DNA possono integrare il loro materiale genetico in quello delle specie ospiti. Alcuni ricercatori ipotizzano addirittura che questo meccanismo sia stato responsabile dell’evoluzione del procariotico primordiale nella cellula eucariotica più complessa. Esempi di questi virus sono l’HIV o quello dell’herpes. I virus come il COVID-19 o la comune influenza non traducono il loro RNA in DNA, ma usano direttamente l’apparato cellulare della cellula ospite per riprodursi. Questo li rende molto più virulenti ma a differenza dei primi, meno complessi nel loro camuffamento.
Il genoma dei coronavirus ha una dimensione compresa tra ~ 26000 e ~ 32000 basi nucleotidiche e codifica per un numero variabile (da sei a undici) di proteine. Il coronavirus COVID-19 contiene circa 30000 basi, la prima parte rappresenta più del 67% dell’intero genoma e codifica per 16 proteine necessarie alla sua riproduzione, mentre il resto per quelle accessorie e strutturali. Nella Figura 2, è riportata una descrizione schematica del genoma del COVID-19. La struttura di diverse proteine non è stata ancora determinata e anche la loro funzione non è ancora ben chiara.
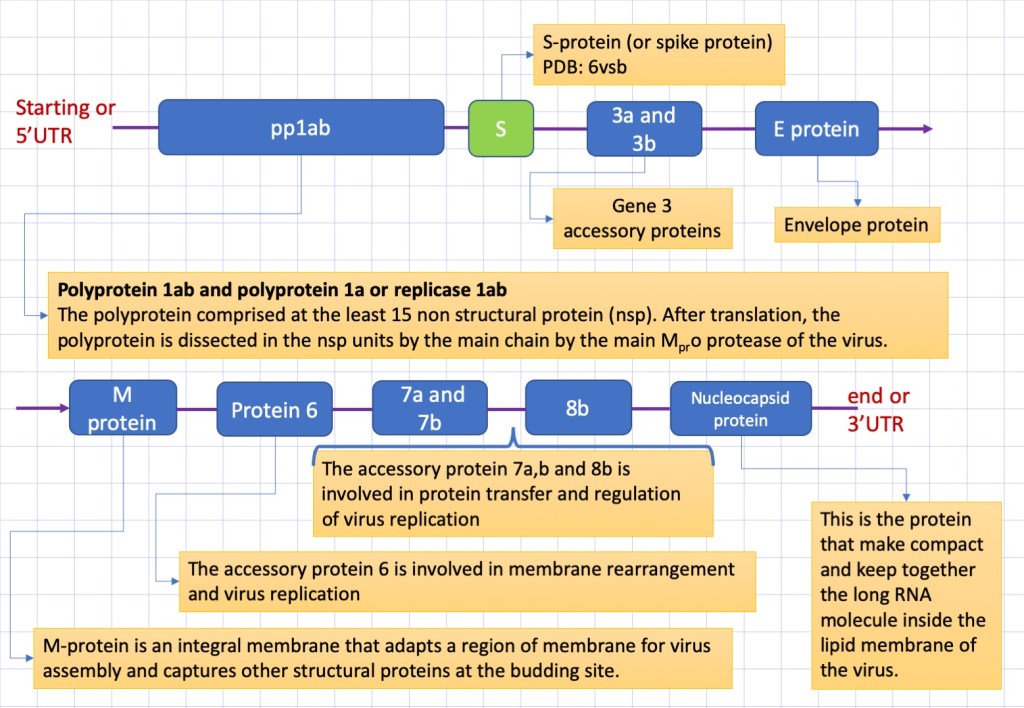
Iniziamo ad analizzare la struttura del virus partendo dall’involucro esterno. Questo è costituito dai lipidi, gli stessi che compongono la membrana delle cellule dell’organismo ospite. Inserite nella membrana ci sono le tre principali proteine strutturali: la proteina S una glicoproteina che sporge dalla superficie della membrana ed è responsabile del legame con il recettore cellulare della cellula ospite, la proteina E (per “envelope“), e la proteina della matrice (M) che servono a stabilizzare il capside che racchiude la catena di RNA. Vediamo più nel dettaglio quello che si conosce sulla natura e la funzione di queste proteine.
La proteina S (S è per il “surface“) o Spike è una glicoproteina che svolge il ruolo essenziale di legarsi con i recettori sulla cellula ospite inducendo la fusione della membrana virale con quella dell’ospite. Il processo innesca l’invasione della cellula ospite. Data la sua importanza, questa proteina è uno dei principali bersagli per i farmaci che si stanno sviluppando contro il virus. La struttura della proteina S nella forma trimerica e nello stato che precede la fusione, è stata recentemente determinata mediante microscopia crioelettronica. Da una serie d’immagini raccolte, è stato possibile ricostruire la struttura tridimensionale della proteina a livello atomico. I modelli molecolari della proteina sono pubblicamente disponibili nel Protein Data Base (PDB) con in codici PDB: 6vsb, 6vxx, 6vyb.
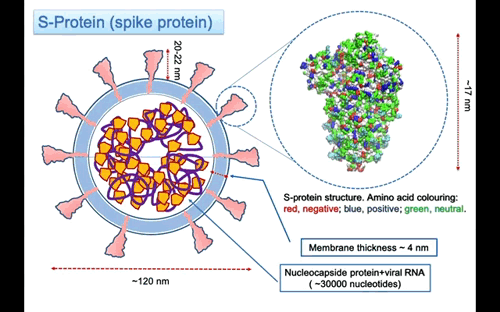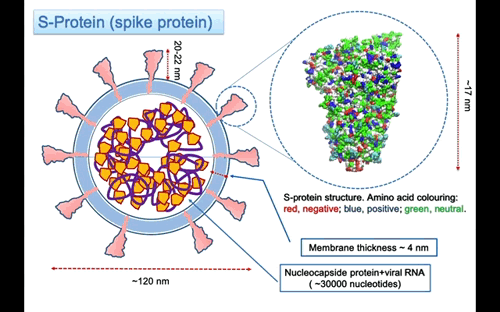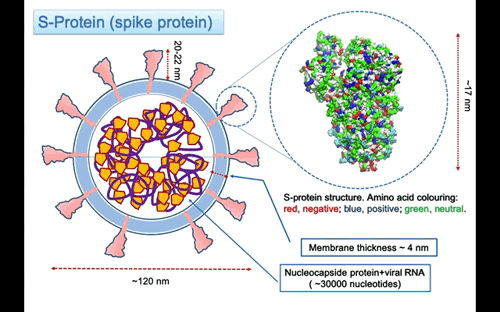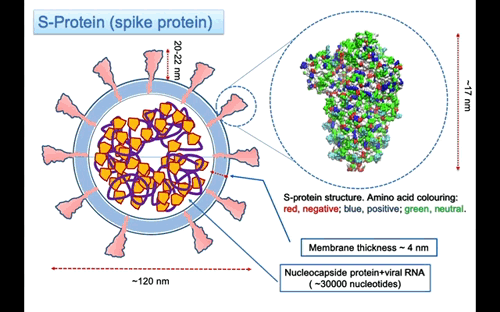
Nella Figura 3, la struttura della proteina S è rappresentata usando, per indicare la posizione degli atomi, sfere di raggio uguale a quello di van der Waals. Le sfere sono colorate in accordo alla carica dell’amminoacido, usando il rosso per amino acidi negativi, blu per quelli positivi e verde per quelli neutri. La proteina è lunga ~ 17 nanometri (nm), ma manca della parte dello stelo formato da tre eliche alpha che penetra nella membrana. Una stima della lunghezza totale della proteina fino alla superficie della membrana è di circa 22-25 nm e circa 32 nm till the other end. Le tre eliche attraversano la membrana lipidica sporgendo nella parte interna con segmenti che probabilmente si ancorano alle proteine del nucleo capside che compattano la lunga molecola di RNA all’interno del virus. La parte superiore della proteina S si estende per circa 
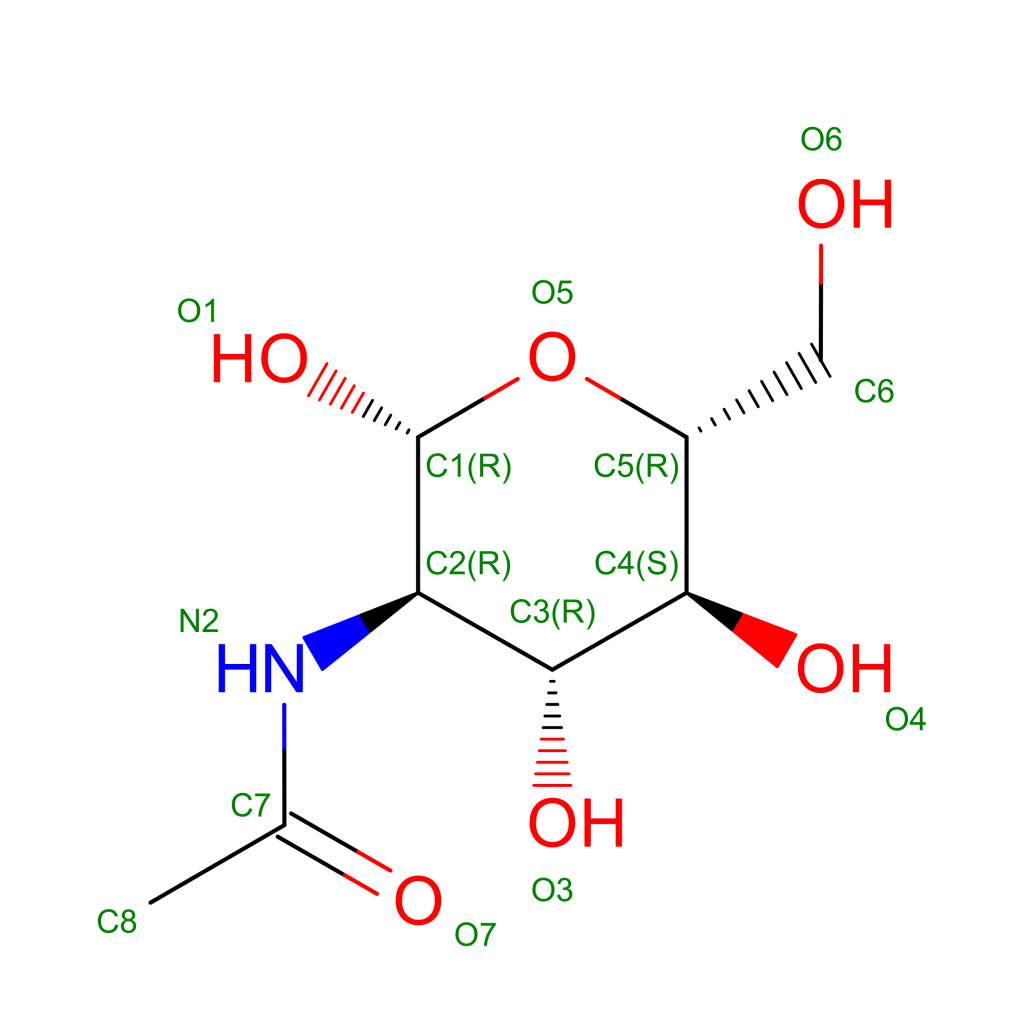
I glicani svolgono una funzione fondamentale nel meccanismo di riconoscimento molecolare dei recettori sulla superfice delle cellule nel nostro corpo. Questa funzione viene sfruttata dai virus per mimetizzarsi ed eludere il nostro sistema immunitario. Fortunatamente, i glicani che ricoprono le proteine sulla membrana esterna di questi virus sono generalmente meno complessi di quelli presenti nell’organismo ospite in questo modo il nostro sistema immunitario impara, anche se più lentamente, a “distinguere” la foresta di canopi zuccherine sui virus e a neutralizzarli. In un recente articolo apparso sulla rivista americana Science [5] è riportata una dettagliata mappatura dei glicani sulla superfice della proteina Spike. Questo è un risultato molto importante poichè permetterà lo sviluppo di vaccini più efficace. Nella struttura risolta della proteina S, sono riportate riportati 66 siti di N-glicosilazione (22 per catena). Nella struttura gli amino acidi sono legati a singole molecole di N-acetil-glucosamina (NAG, vedi formula strutturale in Figura 4) ma l’articolo su Science ha mostrato un a dettagliata mappa dei siti che sono glucosilati con catene di zuccheri di diversa complessità e composizione.
Le unità NAG sembrano distribuite in modo abbastanza uniforme su tutto il trimero di proteine S (vedere la Figura 5).
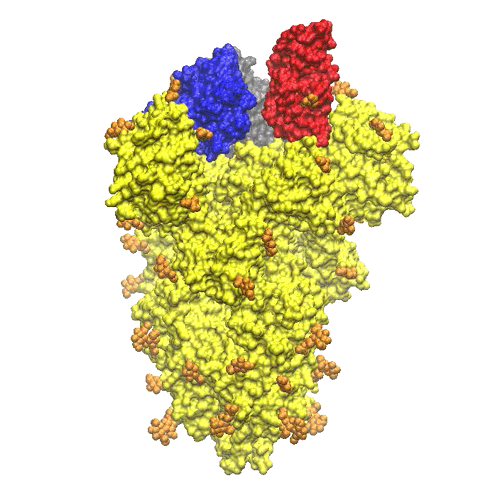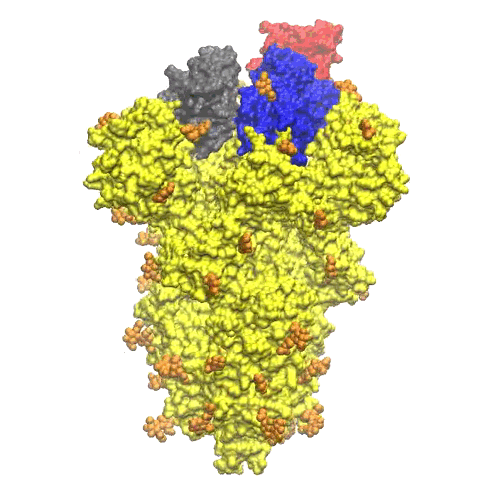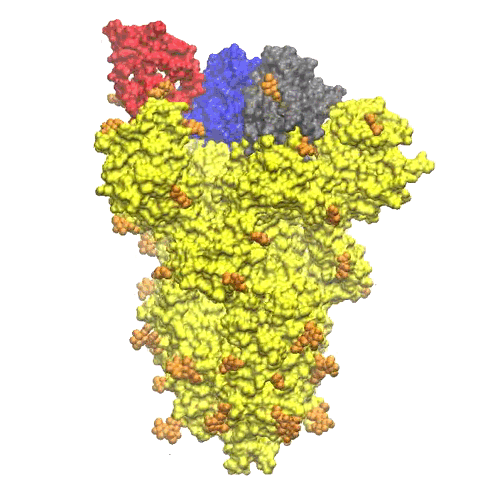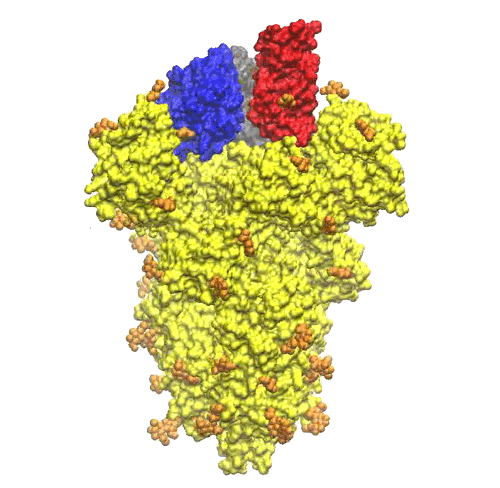
Sulla parte superiore del picco, ci sono tre regioni che sono identificate come domini di legame con il recettore (vedi Figura 6).
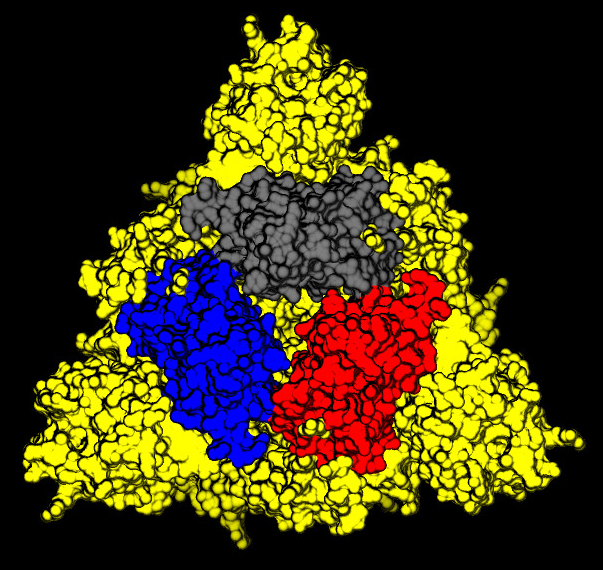
I domini subiscono un movimento di apertura e chiusura attorno a una cerniera. Questo movimento è stato messo in evidenza dalla differenza osservata tra la struttura 6vxx con le regioni chiuse (in Figura 6) e la 6vvy con quelle aperte (Figura 7). Nella struttura rappresentata in Figura 7, la regione di legame in conformazione aperta è colorata in rosso, la stessa regione è chiaramente riconoscibile anche nell’orientamento della proteina in Figura 5.
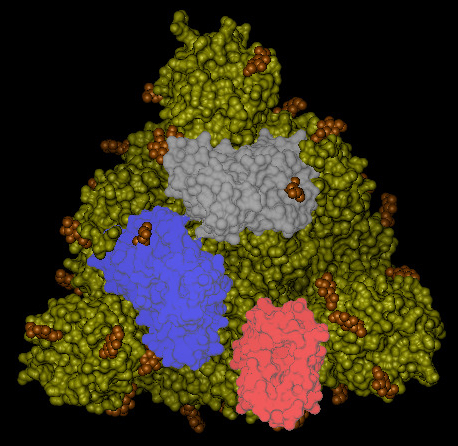

Queste regioni sono coinvolte nel legame con un recettore presente sulle membrane delle cellule dell’ospite. Nel caso del COVID-19, il recettore è stato identificato come l’enzima che converte l’angiotensina 2 (chiamato ACE2). Questo è un enzima attaccato alla superficie esterna (membrane cellulari) delle cellule dei polmoni (ma anche di quello di arterie, cuore, reni e intestino). L’ACE2 abbassa la pressione sanguigna catalizzando l’idrolisi dell’angiotensina II (un peptide vasocostrittore) in angiotensina (un vasodilatatore).
Ringraziamenti
Tutte le figure delle strutture proteiche in questo articolo sono state prodotte utilizzando il software di dominio pubblico Visual Molecular Dynamics (VMD) sviluppato presso l’Università dell’Illinois a Urbana-Champaign [6].
RIFERIMENTI BIBLIOGRAFICI
- Wrapp, D., Wang, N., Corbett, K.S., Goldsmith, J.A., Hsieh, C.L., Abiona, O., Graham, B.S. and McLellan, J.S., 2020. Cryo-EM structure of the 2019-nCoV spike in the prefusion conformation. Science, 367(6483), pp.1260-1263.
- Levine, A.J., 1991. Viruses: A Scientific American Library Book. Henry Holt and Company.
- Wu, A., Peng, Y., Huang, B., Ding, X., Wang, X., Niu, P., Meng, J., Zhu, Z., Zhang, Z., Wang, J. and Sheng, J., 2020. Genome composition and divergence of the novel coronavirus (2019-nCoV) originating in China. Cell host & microbe.
- Yan, R., Zhang, Y., Li, Y., Xia, L., Guo, Y. and Zhou, Q., 2020. Structural basis for the recognition of the SARS-CoV-2 by full-length human ACE2. Science.
- Watanabe, Y., Allen, J.D., Wrapp, D., McLellan, J.S. and Crispin, M., 2020. Site-specific glycan analysis of the SARS-CoV-2 spike. Science.
Lista di altre fonti di materiale informativo
Nucleus Medical Media: https://www.youtube.com/watch?v=5DGwOJXSxqg
RCSBProteinDataBank: https://www.youtube.com/watch?v=s2EVlqql_f8
Scientific Animations: https://www.youtube.com/watch?v=I-Yd-_XIWJg&t=143s
Biolution: https://www.youtube.com/watch?v=I0TmBsHaGmI

